题目描述
译自 POI 2011 Round 1. E「Plot」
给定 n 个点 (P1,…,Pn),将其分成不多于 m 个连续的段:
(Pk0+1,…,Pk1),(Pk1+1,…,Pk2),…,(Pks−1+1,…,Pks),
其中 0=k0<k1<k2<…<ks=n,且对于 i=1,…,s,子序列 (Pki−1+1,…,Pki) 用一个新点 Qi 替代。这时我们说 Pki−1,…,Pki 这些点被「收缩」到了点 Qi,从而产生一个新的点集 Q1,…,Qs。两个点集的相似度定义为 P1,…,Pn 这些点与其对应的「收缩」后的点距离的最大值:
i=1,…,smax(j=ki−1+1,…,kimax(d(Pj,Qi))),
其中 d(Pj,Qi) 表示 Pj 和 Qi 之间的距离,公式为:
d((x1,y1),(x2,y2))=(x2−x1)2+(y2−y1)2
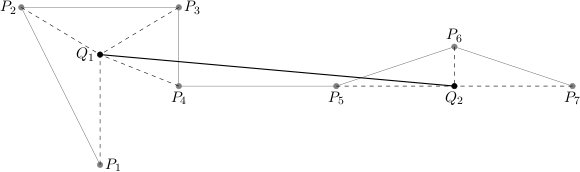
上图为一个将 (P1,…,P7) 收缩为 (Q1,Q2) 的例子,其中 (P1,…,P4) 被收缩为 Q1,(P5,P6,P7) 被收缩为 Q2.
给定 n 个点组成的序列,你需要将其「收缩」为最多 m 个点,使得相似度最小。原序列可以任意切割。受限于浮点数的精度限制,只要答案比最优解多出不超过 0.000001 即算正确。
输入格式
第一行两个整数 n 和 m,1≤m≤n≤100000,用一个空格分开。
接下来 n 行每行两个整数,用一个空格分开。第 i+1 行两个整数 xi,yi(−1000000≤xi,yi≤1000000),表示 Pi 的坐标为 (xi,yi).
输出格式
第一行一个实数 d,表示与原序列的相似度。
接下来一个整数 s,表示收缩后点集的大小。
接下来 s 行表示 Qi,…,Qs 的坐标。每行两个整数 ui 和 vi 表示 Qi 的坐标 (ui,vi)。
实数应保留小数点后最多 15 位。
样例
7 2
2 0
0 4
4 4
4 2
8 2
11 3
14 2
3.00000000
2
2.00000000 1.76393202
11.00000000 1.99998199
数据范围与提示
Task author: Jakub Pawlewicz.
Uncompleted SPJ: ceba
SPJ: Tangjiaming
翻译:vincent163